
As applications become more centralized, the data resources they require are often located in remote customer data centers, which can be difficult to access. This poses challenges for product and engineering teams who want to expand their offerings and simplify the management of cloud applications, but are limited by the need to work with data resources that must remain behind firewalls in these remote locations.
Data meshes have come to be the most effective way to integrate these sources into an application without requiring a lift and shift of the data or compromising security.
You can think of a data mesh as a connective layer spread across multiple data locations, types and sources, with a common method for accessing that data. This frees an application to use, manage and transform data within the data mesh fabric without the need for physical proximity and the burden of ‘networking’.
When approaching the build-out of a data mesh, questions around hardware requirements, ongoing maintenance, security, and other complexities always arise as people begin understanding the difference between a fully integrated data mesh versus the status quo of assembling a collection of non-integrated networked endpoints.
At first glance, data meshes may sound like a complete overhaul of IT/Product infrastructure, but they are actually far easier to achieve than many realize.
To fully internalize the simplicity of creating a data mesh, let’s step through the process of using the Trustgrid Data Mesh Platform to establish a data mesh between an application environment and distributed data sources.
Deployment
Because we are creating a way for centralized cloud applications to access data, deployment starts by initializing a centralized gateway that will be aggregating all of the data sources for an application to consume.
This is created through the use of gateway nodes to create a Virtual Data Warehouse. This Virtual Data Warehouse allows cloud applications developers to map access to remote data points.
This software-defined gateway is run adjacent to the application it serves and can be deployed within a cloud environment or in a data center.
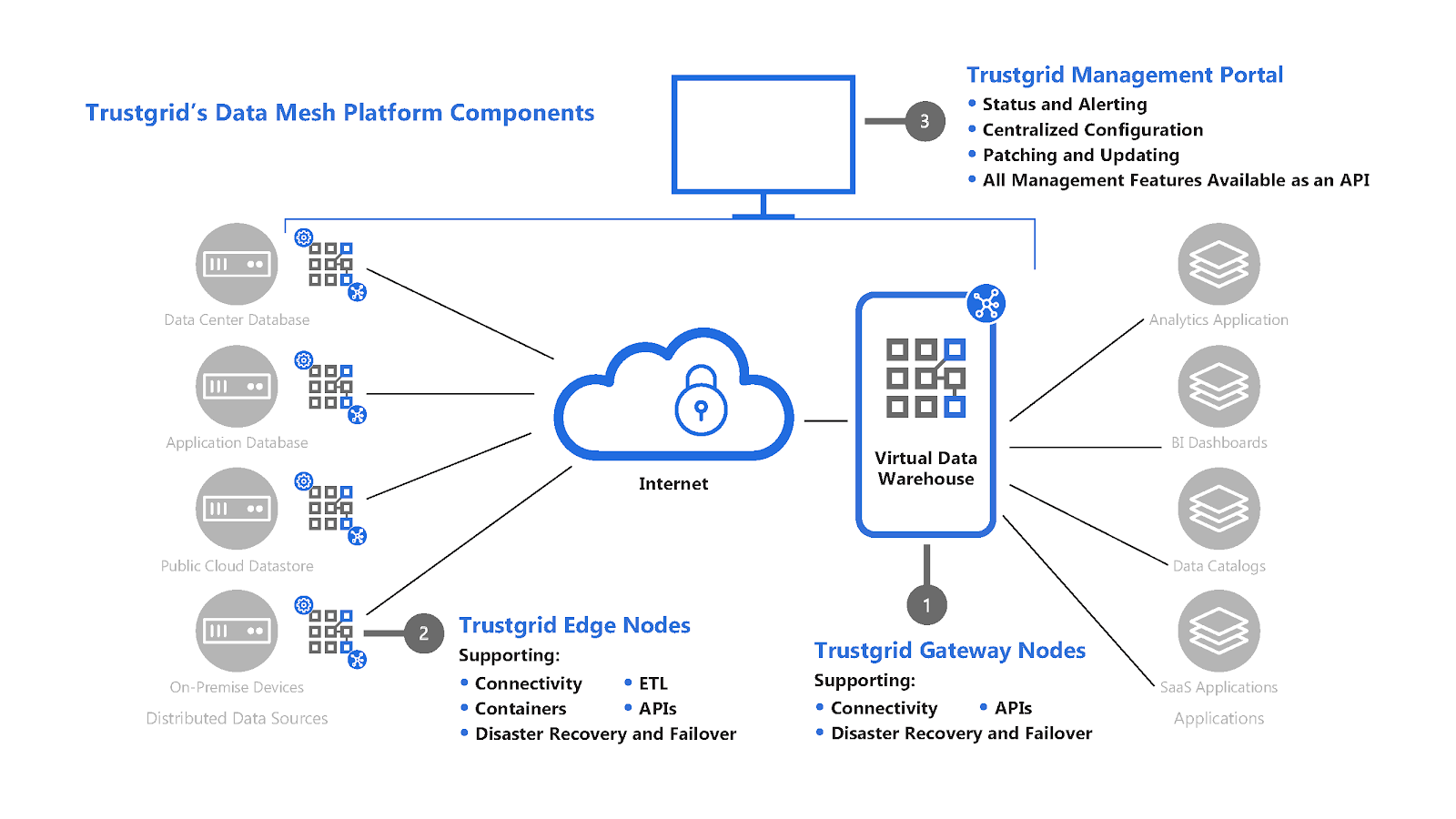
This Virtual Data Warehouse allows for the virtual aggregation of data so that an application (or many applications) can easily consume it. Once a data source is added to the Virtual Data Warehouse an application has secure, real-time, persistent access to that data set.
Connecting Any Data Source
Data is heterogeneous. Data sets vary by size, schema, surrounding IT environment, security requirements and a number of other factors that complicate its integration with another data set. When these data sets are controlled by another organization, it further complicates an already challenging task.
In order to virtually aggregate every required data source and make them accessible to an application, we must have an easy way to connect to them. This data connection needs to be created in a way that is common and ubiquitous across all connections in your data mesh.
In a data mesh, these connections are established by an appliance that acts as an endpoint or node.
Because data meshes must connect data living across a variety of environments there must be flexibility in the types of endpoint appliances required.
Trustgrid’s Data Mesh Platform uses software-defined nodes that can be deployed through a hardware device, virtual appliance or cloud endpoint. These software nodes can be dropped into any environment and do not require the rip and replace of any existing equipment.
- Hardware device – The hardware device is one of the easiest methods of deployment because Trustgrid handles all of the software imaging, logistics and deployment support for the end-user. A hardware appliance is ideal for environments with limited onsite support.
- Virtual Appliance – For those that prefer not to deal with the logistical or cost considerations of a physical hardware appliance, Trustgrid’s Data Mesh Platform can create a node using only software. This virtual appliance works in any environment supporting VMWare vSphere. And is ideal for environments with DevOps management and support.
- Cloud End Points – For cloud-native data stores the platform supports AWS, Azure, Google Cloud and Oracle Cloud to easily form endpoint connections to public cloud environments.
Each of these form factors has unique advantages and can be mixed and matched based on the environment they will be deployed in and availability of onsite support staff.
Connect
After selecting the vehicle for deployment, some basic information on the IT environment must be gathered to ensure quick, secure and turnkey deployment of new connections.
For hardware-based installations, the device must simply be provided power and an ethernet connection into the same network switch as the data source. This allows for the device to automatically establish a connection, phone home and receive any immediate or future configuration changes within minutes.
For virtual and cloud appliances, a self-contained software package is deployed in the destination environment. Once initiated, the software acts as a secure endpoint, but without the use of a dedicated, single-purpose device.
This process can be repeated an unlimited number of times to establish the fabric of connectivity for your data mesh. For connections that require high availability, clustered nodes can be paired with automated failover features that ensure an ‘always-on’ connection.
When overlapping subnet issues arise (when a data source and application are trying to use the same IP addresses) the data mesh easily resolves this by creating virtual IP spaces within the software. These virtual IPs are natively logged and mapped to the Virtual Data Warehouse so that developers no longer have to keep track of them separately.
Additionally, data adaptors and connectors can be run in containers on these endpoints to further extend the centralized application’s utility, as well as aiding in the ability to normalize data at the edge before it is accessed by the virtual data warehouse.
Manage
Once all of the endpoints have been established, the Trustgrid Management Portal is used to centrally manage visibility, control, and support of the new data mesh.
All connected resources can now be centrally monitored, patches and updates can be applied without any effort required by the data endpoints, and APIs can be created from the new virtual data warehouse to orchestrate access to the aggregated data.
From this portal, connections can be enabled and disabled with the touch of a button and anomalies in usage can be detected in real-time.
While visibility and control of connected data sources is centralized in the portal, all connections between the cloud applications and data sources are end-to-end encrypted while advanced security features such as certificate-based authentication and access control lists (enabling zero-trust access) ensure that sensitive data is only accessible to approved entities.
Tackling the complexities of accessing distributed and siloed data sources may seem intimidating. Quickly spinning up new locations, standardizing access to diverse data sources, and centralizing management with legacy tools IS intimidating and is usually outside the core competencies of an application provider.
The use of legacy technologies (or attempting to internally build tools) to solve modern connectivity problems will inevitably lead to additional costs, delays and operating inefficiencies
The good news for every software provider is that all of these challenges are already solved and available as a turnkey platform and managed service.
Giving cloud applications access to distributed data sources has actually never been less intimidating.
Learn more about Trustgrid’s Data Mesh Platform.